Abstract
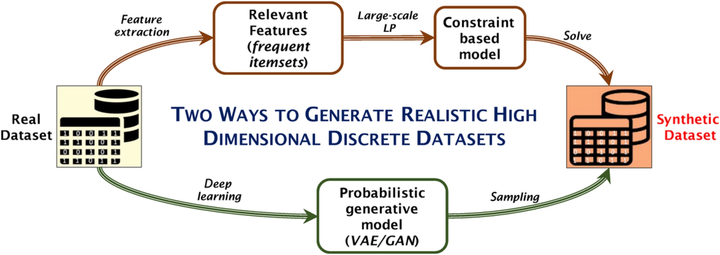
Abstract The development of platforms and techniques for emerging Big Data and Machine Learning applications requires the availability of real‐life datasets. A possible solution is to synthesize datasets that reflect patterns of real ones using a two‐step approach: first, a real dataset is analyzed to derive relevant patterns and, then, to use such patterns for reconstructing a new dataset that preserves the main characteristics of . This survey explores two possible approaches: (1) Constraint‐based generation and (2) probabilistic generative modeling. The former is devised using inverse mining () techniques, and consists of generating a dataset satisfying given support constraints on the itemsets of an input set, that are typically the frequent ones. By contrast, for the latter approach, recent developments in probabilistic generative modeling () are explored that model the generation as a sampling process from a parametric distribution, typically encoded as neural network. The two approaches are compared by providing an overview of their instantiations for the case of discrete data and discussing their pros and cons. This article is categorized under: Fundamental Concepts of Data and Knowledge > Big Data Mining Technologies > Machine Learning Algorithmic Development > Structure Discovery