Giuseppe Manco
Director of Research at the Italian National Research Council
Istituto di Calcolo e Reti ad Alte Prestazioni (ICAR-CNR)
Biography
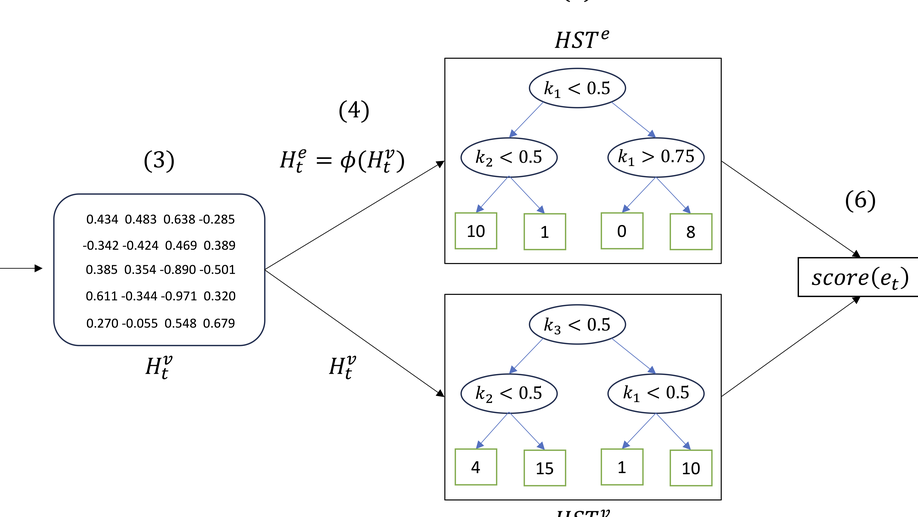
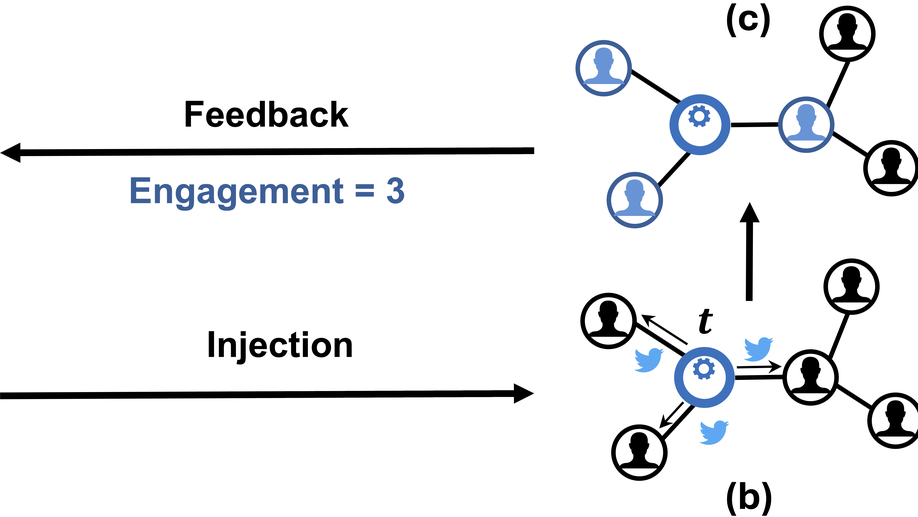
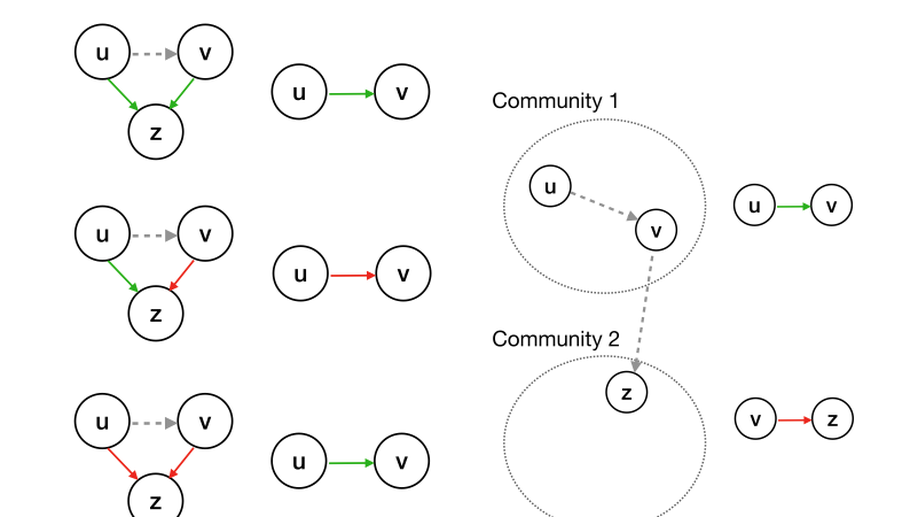
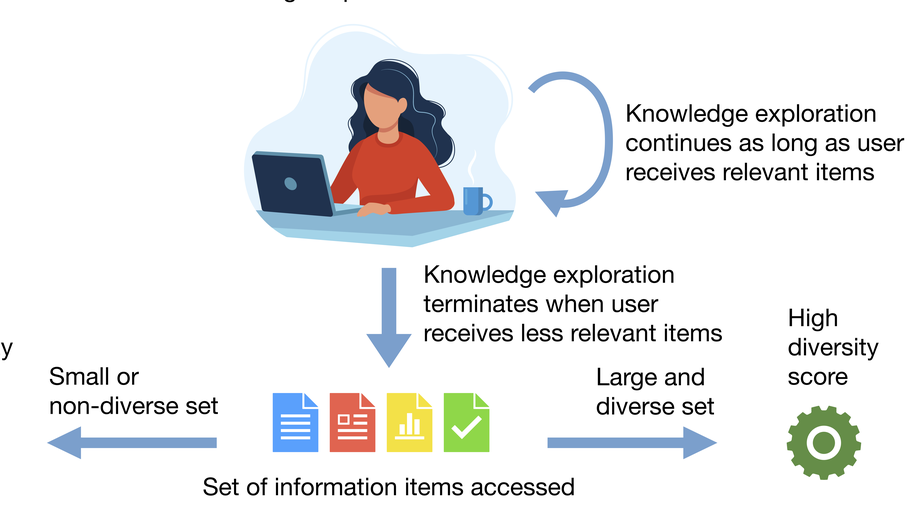
Giuseppe Manco is Director of Research at the Institute of High Performance Computing and Networks of the National Research Council of Italy. His research interests include User Profiling and Behavioral Modeling, Social Network Analysis, Information Propagation and Diffusion, Recommender Systems, Machine Learning for Cybersecurity.
Expert on data science, data analytics and enabling technologies for data analytics. Interested in new frontiers of Computer Science and Technology aimed at analyzing Complex Big Data. Co-founder of Open Knowledge Technologies (OKT), a spin-off company of University of Calabria aimed at bringing innovation from academia to industry on the specific topics of Artificial Intelligence and Cybersecurity.
Interests
- Machine Learning
- Behavioral Modeling
- Recommender Systems
- Cybersecurity
Education
PhD in Computer Science, 2001
University of Pisa
MSc in Computer Science
University of Pisa